
How do employers distinguish Data Scientists and Data Analysts?
Motivation
Being a data practitioner, I often get asked the question What is the difference between a Data Scientist and a Data Analyst? Though I usually answer this question empirically, I decided to take a data-driven approach and build a model to more systematically identify the distinction between these two roles.
Process
What I ended up doing was collecting job descriptions for Data Scientist and Data Analyst roles posted by the big tech companies in Silicon Valley on job boards and training a model on a subset to see if I could accurately predict the remaining titles from just the job descriptions.
For a more in depth explanation of the process and accompanying code for this project, please see my my github repo.
Results
I ended up training a Multinomial Naive Bayes model to predict the job titles. My final Multinomial Naive Bayes model had an ROC AUC of 88%. Unsurprisingly, the top key words/phrases for Data Scientist were: machine learning, models, algorithms while that for Data Analysts were: reports, dashboards, and excel.
Takeaways
Examining the results that my model classified incorrectly actually gives insight into employers and their expectations.
There are several reasons why a company might choose to display a title where the description does not match the role. Lyft, for example, on their blog, wrote the following article What’s in a name?, where they explained that they strategically chose to change the title of a Data Analyst to a Data Scientist to retain talent (in my model, this role comes up as a false negative). However, instead of encompassing both roles in one title, they updated that of Data Scientist to Research Scientist. Others have done it to attract talent and get a pool of applicants that are simply drawn to the Sexiest Job of the 21st Century, as proclaimed by Harvard Business Review. While others have changed the title to Data Scientist, but kept the Data Analyst description to attract more skilled workers.
I am curious if other companies will follow this example and broaden the definition of a Data Scientist. Will more companies use these two terms interchangeably or create new terminology like research scientist?
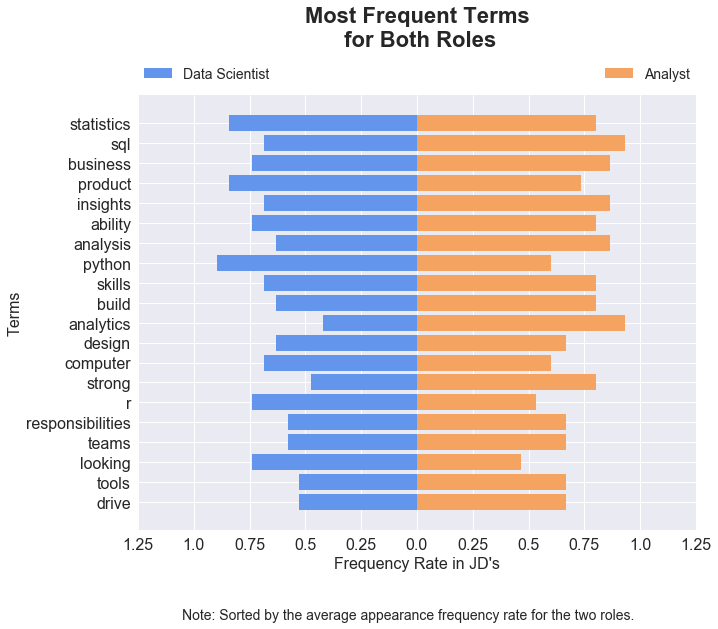
Frequent terms establish the baseline knowledge expected in both roles, while frequent but unique terms per role highlight key differences.
It is no surprise that SQL and analysis show up frequently in both postings (see chart below). What is interesting, however, is that statistics shows up in both. Context is very important; the words that show up surrounding this term provide additional information about the level of expertise required. Upon further inspection, it looks like this term frequently shows up alongside a list of other quantitative degrees, for both roles, so it is less surprising than it was at initial glance.
Another term that appears frequently for both is Python. The frequency of which this word shows up for Data Scientist roles is, however, considerably higher than the times it appears in Data Analyst JDs. Almost 90% of the data science roles contain the key term, while only 60% of the Data Analyst JDs have it, indicating that Python is an expected skill for a Data Scientist.
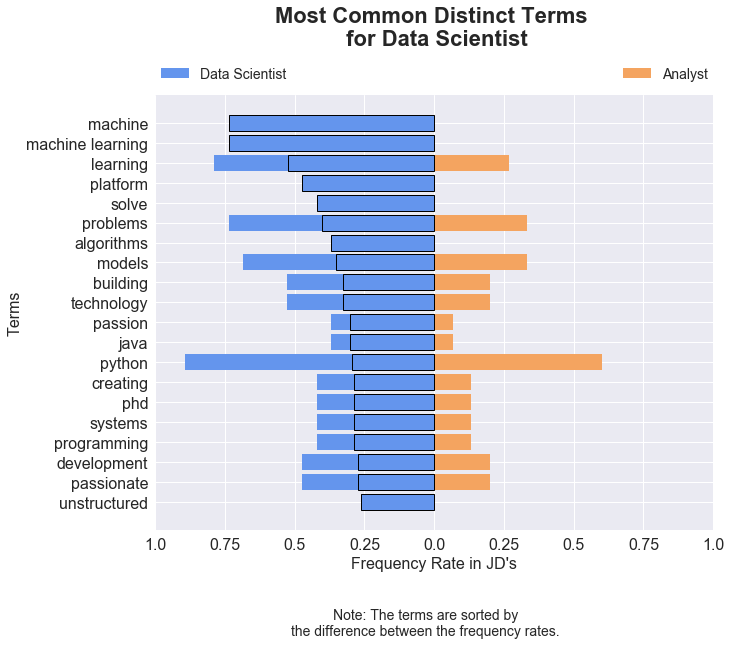
Surveying the top terms for Data Scientist, results in a collection of words that are more technical in nature. Some of the top terms are: machine learning, platform, algorithms, models, Java, programming, development (see chart below). Because data science is more of a mix of a statistics and a computer science, these terms are not surprising at all.
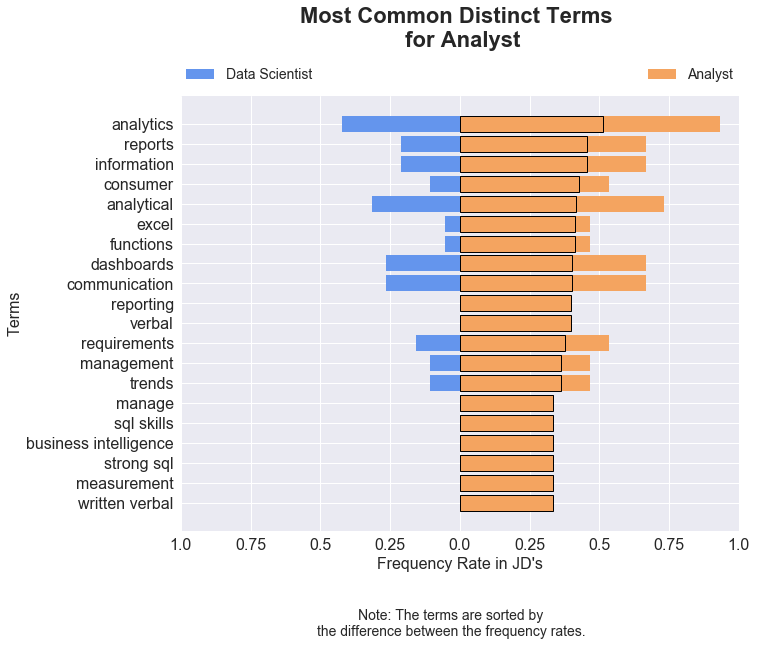
For Data Analysts, the key words tend to focus more on information dissemination, whether it be through through verbal or written form: reports, reporting, dashboards, communication, verbal. Data retrieval and organization is another theme that comes up: excel, strong SQL, SQL skills, trends.
Applications
For someone who is looking to go into the field of analytics, perhaps focusing on the skills that overlap between the two roles could be a good starting point. However, for someone looking to transition from a Data Analyst role to a Data Scientist role, focusing on the most frequent distinct skills could be of better use.
For employers uncertain what to add to their job descriptions, the above key terms could be used to determine what is the industry defacto and then modify the requirements based on company needs.
Final Thoughts
Though there is quite a bit of overlap between these two roles, there are enough unique key terms that are common for one role but not the other that help to differentiate the roles. As a result, the model did fairly well in distinguishing these two roles. However, as industry standards change and new hybrid roles are created (without modification to the titles), distinguishing these roles will become harder.
To address this role inflation, it might be interesting to instead use an unsupervised clustering model to see what roles get grouped and whether new titles could be derived from these clusters.
Leave a Comment